


Esta semana instale varias aplicaciones al cluster , instalamos los nodos de los demás compañeros al cluster
también realice la documentación sencilla de todo lo que se ha instalado en el cluster
http://node1.hopto.org/Documentacion.zip
Actualice ganglia a 2.0
https://node1.hopto.org
Nominaciones
Juancarlos, Pepe Gonzales y osvaldo por su ayuda a configurar el cluster :)
jueves, 24 de mayo de 2012
miércoles, 16 de mayo de 2012
Reporte de actividades


- Esta semana se implemento el sistema del monitoreo se encuentra montado en el nodo maestro que es el servidor que se encuentra en mi casa.
- Se probo ejemplos de MPICH2, Python y se piensa instalar Jhon the ripper para decifrar contraseñas ya que podria servir para el proximo semestre de criptografia.
- Se cambio el protocolo de TCP a UDP se comprobo que al ejecutar un codigo se tardo 1.5 segundos en TCP y en UDP fue en 0.65 segundos en arrojar los resultados
- Se comprobó que cuando un nodo se desconecta no pasa nada el cluster sigue funcionando
- Se trabajo en conjunto con juan Carlos para realizar la automatización de tareas
Nominaciones:
Juan Carlos
Alex Villarreal Gaytan
Configurando los Nodos Ganglia

Configuración si estas en la VPN
Archivos de configuración y manual
Configuración fuera de la VPN
Archivos de configuración y manual
Contiene todo lo necesario para instalar ganglia en los nodos del cluster
Ganglia

Para el monitoreo del cluster se ha elegido Ganglia por sus ventajas y porque está ampliamente testeado en muchos cluster que están en la actualidad funcionando.
Los componentes principales de Ganglia son:
- gmond: demonio que se encarga de recoger y distribuir el estado del nodo. Debe correr en TODOS los nodos
- gmetad: sirve de parser, obtiene los datos de los gmond y los procesa. Sólo corre en el nodo front-end, es decir, en el nodo con el que nos comunicamos
- web front-end: es una interfaz web en php que nos muestra el estado del cluster de manera gráfica. Se instala en el nodo que tenga el gmetad. Está escrito en php4 y no se visualiza bien si utilizamos php5. Se puede obtener las últimas versiones de php4 para openSuSE en esta dirección http://download.opensuse.org/repositories/home:/michal-m:/php4/openSUSE_10.2/ (se puede añadir como canal RPM-MetaData de Smart)
sudo apt-get install rrdtool librrds-perl librrd2-dev php5-gd
wget http://downloads.sourceforge.net/ganglia/ganglia-3.0.7.tar.gz
cd ganglia* ./configure --with-gmetad make
mkdir /var/www/ganglia sudo cp -r web/* /var/www/ganglia
gmond se ha de instalar en TODAS las máquinas a monitorizar.
En la máquina front-end del cluster instalamos gmetad y el web-front-end. Para compilar el gmetad hay que añadir a la orden de configuración: ./configure –with-gmetad. El fichero de configuración de gmetad, gmetad.conf se puede encontrar en el directorio correspondiente dentro de las fuentes y se puede copiar a /etc. La instalación de este último es solo descomprimir las fuentes dentro del DocumentRoot del servidor web.
Opcionalmente, podemos instalar gexec, para correr la misma orden en varias o todas las máquinas del cluster simultáneamente.
CONFIGURACIÓN
gmond: el archivo de configuración de gmond es /etc/gmond.conf Para crearlo se puede usar gmond -t > /etc/gmond.conf que crea un archivo de configuración por defecto. Lo más importante de este archivo es:
Dentro de globals:gmetad: El principal aspecto a configurar son las fuentes de donde recopila la información. Es de la forma
daemonize = yes # para que corra como demonio del sistema
gexec = yes # si tenemos instalado gexec
Dentro de cluster:
name = “nombre” # nombre del cluster, es mejor especificar alguno
udp_send_channel: para enviar la información del host. Todos los nodos de un mismo cluster han de tener la misma configuración aquí. Se puede enviar por multicast o unicast y se pueden poner todos los canales de envío que se deseen (varios unicast, varios multicast,…)
- Multicast: utilizar una dirección IP multicast. Deberemos variarla y poner cada cluster con una IP multicast diferente. Ejemplo: 239.2.11.72, 239.2.11.73,… La que asignemos aquí también la tenemos que cambiar en udp_recv_channel. El puerto no es necesario modificarlo y es mejor dejarlo así. Ejemplo
udp_send_channel { mcast_join = 239.2.11.71 port = 8649 }- Unicast: se manda la información al nodo principal directamente. Puede ser más útil en algunos casos que el multicast dé problemas.
udp_send_channel { host = 192.168.3.4 port = 8649}
udp_recv_channel: para el nodo encargado de recibir toda la información y crear el fichero XML. Pueden tenerlo todos los nodos o sólo algunos. Generalmente, irá en el nodo cabecera (con gmetad y la interfaz web).
- Multicast
udp_recv_channel { mcast_join = 239.2.11.71 bind = 239.2.11.71 port = 8649 }Posteriormente, viene una lista con las métricas que serán recolectadas por gmond. Su configuración por defecto es correcta, aunque se puede modificar la frecuencia con la que se recolectan y añadir o borrar algunos.
- Unicast
udp_recv_channel { port = 8666 family = inet4 # o inet6 }
Más información en: http://ganglia.sourceforge.net/docs/gmond.conf.html
data_source “nombre” [intervalo de sondeo] dirección1:puerto dirección2:puerto…
Puede haber tantas fuentes como se desee. Para ello, se añade una línea como la de arriba por fuente. Por ejemplo
data_source “Proteus” 192.168.2.4, 192.168.2.5
data_source “Servidor” 127.0.0.1
en la primera fuente, hay 2 ips redundantes, por si alguna de las máquinas se cae.
Hay que crear el directorio donde gmetad almacenará los datos de los distintos nodos, en formato de base de datos round-robin. Este directorio viene dado por el atributo rrd_rootdir del fichero de configuración gmetad.conf. Por defecto, es el directorio /var/lib/ganglia/rrds y a de pertenecer al usuario nobody.nobody
web front-end
Se puede elegir entre los templates disponibles.
Monitorización de la temperatura
Por defecto, Ganglia no monitoriza la temperatura pero podemos añadir esta opción utilizando la herramienta gmetric que incorpora. Esta herramienta permite añadir las métricas que se deseen desde la línea de comandos. Más información: http://ganglia.sourceforge.net/docs/ganglia.html#gmetricPara medir la temperatura, usaremos el programa sensors. Lo primero de todo es configurarlo con sensors-detect. Este programa busca el tipo de sensores de temperatura, revoluciones de ventiladores, voltaje,… que tiene nuestro equipo y crea el fichero /etc/sysconfig/lm_sensors donde se indica que módulos cargar para manejarlos. Si los sensores no estuvieran soportados por el kernel, tendríamos que buscar las correspondientes fuentes y recompilar el kernel. También se crea el fichero /etc/init.d/lm_sensors para cargar estos módulos automáticamente al inicio del sistema.
Sólo nos falta enviar periódicamente la información de los sensores. Para ello, añadimos una entrada a cron del tipo:
*/5 * * * * root /admin/ganglia/temp.sh
donde temp.sh es un fichero que coge la información de sensors y utiliza gmetric para enviarla:
#!/bin/bash
GMETRIC=/usr/bin/gmetric
SENSORS=/usr/bin/sensors
# send cpu temps if gmond is running
`/sbin/service gmond status > /dev/null`
if [ $? -eq 0 ]; then
# send cpu temperatures
let count=0
for temp in `${SENSORS} | grep “CPU Temp” | cut -b 12-16`; do
$GMETRIC -t float -n “cpu${count}_temp” -u “C” -v $temp
let count+=1
done
# send cpu fan speed
let count=0
for fan in `${SENSORS} | grep CPU_Fan | cut -b 12-15`; do
$GMETRIC -t uint32 -n “cpu${count}_fan” -u “RPM” -v $fan
let count+=1
done
fi
miércoles, 9 de mayo de 2012
Reporte de Actividades
Esta semana se trabajo en tener la interfaz para el portal del Cluster se integro una web basada en SSH :
http://en.wikipedia.org/wiki/Web-based_SSH
http://liftoffsoftware.com/Products/GateOne
http://code.google.com/p/shellinabox/


Nominaciones:
Juan Carlos http://jcecdps.blogspot.mx/2012/05/dps-class-benchmarks.html
Osvaldo : http://4imedio.blogspot.mx/2012/05/reporte-semana-14-paralelos.html
http://en.wikipedia.org/wiki/Web-based_SSH
http://liftoffsoftware.com/Products/GateOne
http://code.google.com/p/shellinabox/


También se hicieron pruebas sobre PVM
Se instalo y se corrieron ejemplos
(Esta en proceso un tutorial para la instalacion de PVM)
Para compilar
Codigo Esclavo
Compilar
Nominaciones:
Juan Carlos http://jcecdps.blogspot.mx/2012/05/dps-class-benchmarks.html
Osvaldo : http://4imedio.blogspot.mx/2012/05/reporte-semana-14-paralelos.html
Parallel Processing Clusters & PVM
 PVM (Parallel Virtual Machine) is a software package that permits a heterogeneous collection of Unix and/or Windows computers hooked together by a network to be used as a single large parallel computer. Thus large computational problems can be solved more cost effectively by using the aggregate power and memory of many computers. The software is very portable. The source, which is available free thru netlib, has been compiled on everything from laptops to CRAYs.
PVM (Parallel Virtual Machine) is a software package that permits a heterogeneous collection of Unix and/or Windows computers hooked together by a network to be used as a single large parallel computer. Thus large computational problems can be solved more cost effectively by using the aggregate power and memory of many computers. The software is very portable. The source, which is available free thru netlib, has been compiled on everything from laptops to CRAYs.
PVM enables users to exploit their existing computer hardware to solve much larger problems at minimal additional cost. Hundreds of sites around the world are using PVM to solve important scientific, industrial, and medical problems in addition to PVM's use as an educational tool to teach parallel programming. With tens of thousands of users, PVM has become the de facto standard for distributed computing world-wide.
freely available network clustering software (http://www.csm.ornl.gov/pvm/) that provides a scalable network for parallel processing. Developed at the Oak Ridge National Lab and similar in purpose to the Beowulf cluster, PVM supports applications written in Fortran and C/C++. In this article, I explain how to set up parallel processing clusters and present C++ applications that demonstrate multiple tasks executing in parallel.
Setting up PVM-based parallel processing clusters is straightforward and can be done with existing workstations that are also used for other purposes. There is no need to dedicate computers to the cluster; the only requirements are that the workstations must be on a network and use UNIX/Linux. PVM creates a single logical host from multiple workstations and uses message passing for task communication and synchronization
My motivation for setting up a parallel processing cluster was to provide a system that students could use for coursework and research projects in parallel processing. My specific goals were to set up a working cluster and demonstrate with test software that multiple tasks could execute in parallel using the cluster.
Why Use PVM?
Granted, there is other software—most notably Beowulf—for clustering workstations together for parallel processing. So why PVM? The main reasons I decided to use PVM were that it is freely available, requires no special hardware, is portable, and that many UNIX/Linux platforms are supported. The fact that I could use Linux workstations that were already available in our computer lab without dedicating the use of those machines to PVM was a major advantage for it.
Other important PVM features include:
A PVM cluster can be heterogeneous, combining workstations of different architectures. For example, Intel-based computers, Sun SPARC workstations, and Cray supercomputers could all be in the same cluster. Also, workstations from different types of networks could be combined into one cluster.
PVM is scalable. The cluster can become more robust and powerful by just adding additional workstations to the cluster.
PVM can be configured dynamically by using the PVM console utility or under program control using the PVM API. For example, workstations can be added or deleted while the cluster is operational.
PVM supports both the SPMD and MPMD parallel processing models. SPMD is single program/multiple data. With PVM, multiple copies of the same task can be spawned to execute on different sets of data. MPMD is multiple program/multiple data. With PVM, different tasks can be spawned to execute with their own set of data.
How PVM Works
A PVM background task is installed on each workstation in the cluster. The pvm daemon (pvmd) is used for interhost communication. Each pvmd communicates with the other pvm daemons via User Datagram Protocol (UDP). PVM tasks written using the PVM API communicate with pvmd via Transmission Control Protocol (TCP). Parallel-executing PVM tasks can also communicate with each other using TCP. Communication between tasks using UDP or TCP is commonly referred to as "communication using sockets"
The pvmd task also acts as a task scheduler for user-written PVM tasks using available workstations (hosts) in the cluster. In addition, each pvmd manages the list of tasks that are running on its host computer. When a parent task spawns a child task, the parent can specify which host computer the child task runs on, or the parent can defer to the PVM task scheduler which host computer is used.
A PVM console utility gives users access to the PVM cluster. Users can spawn new tasks, check the cluster configuration, and change the cluster using the PVM console utility. For example, a typical cluster change would be to add/delete a workstation to/from the cluster. Other console commands list all the current tasks that are running on the cluster. The halt command kills all pvm daemons running on the cluster. In short, haltessentially shuts the cluster down.
The PVM console utility can be started from any workstation in the cluster. For example, if workstations in the cluster are separated by some physical distance, access to the cluster may be from different locations. However, when the cluster is shut down, the first use of the PVM console utility restarts the PVM software on the cluster. The machine on which the first use of the console utility occurs is the "master host." The console utility starts the pvmd running on the master host, then starts pvmd running on all the other workstations in the cluster. The original pvmd (running on the master host) can stop or start the pvm daemon on the other machines in the cluster. All console output from PVM tasks is directed to the master host. Any machine in the cluster can be a master host. Once the cluster is started up, only one machine in the cluster is considered the master host.
Examples
miércoles, 2 de mayo de 2012
Reporte de actividades
Esta semana se esta trabajando en diseñar el portal para ejecutar los trabajos del cluster se realizaron pruebas de cliente y servidor SSH
Cliente:
http://code.google.com/p/shellinabox/
Servidor
https://github.com/liftoff/GateOne/blob/master/gateone/terminal.py
Cliente:
http://code.google.com/p/shellinabox/
Servidor
https://github.com/liftoff/GateOne/blob/master/gateone/terminal.py
Tecnologia Grid
INTRODUCCIÓN
Las tecnologías grid permiten que los ordenadores compartan a través de Internet u otras redes de telecomunicaciones no sólo información, sino también poder de cálculo (grid computing) y capacidad de almacenamiento (grid data). Es decir, en el grid no sólo se comparten contenidos, sino también capacidad de procesamiento, aplicaciones e incluso dispositivos totalmente heterogéneos (sensores, redes, ordenadores, etc.).
El término grid computing viene a raíz de la analogía con la red eléctrica (electric power grid): nos podemos enchufar al grid para obtener potencia de cálculo sin preocuparnos de dónde viene al igual que hacemos cuando enchufamos un aparato eléctrico. Este innovador paradigma de computación distribuida es propuesto por Lan Foster y Carl Kesselman a mediados de los años 90, como una revolucionaría técnica para resolver problemas complejos entre diversas organizaciones optimizando costes y tiempo.
Un caso típico de entorno grid sería el descrito a continuación. Imaginemos a un científico que quiere ejecutar un programa creado por un colega. Si contase con una infraestructura como la de grid, no necesitaría instalar dicho programa en su máquina. En lugar de ello, solicitaría al grid que lo ejecutase remotamente en la computadora que almacena ese programa. En el caso de que la máquina estuviese ocupada, el sistema grid buscará automáticamente a través de Internet una copia del programa deseado en otras computadoras desocupadas, sin importar que dichas máquinas estuviesen situadas en otro punto del planeta, y lo ejecutaría allí.
Evidentemente, hacer esto no es nada trivial, y surgen preguntas como: ¿Cómo decido qué recursos forman parte del grid o no? ¿Cómo decido a qué recurso se dirige un programa o problema concreto? ¿Cómo divido un programa que va a ejecutarse en estas condiciones? ¿Cómo sabe una organización que sus recursos no están siendo abusados o empleados de forma maliciosa?... La computación grid, precisamente, se centra en solucionar todas estas cuestiones.
EVOLUCIÓN DE LA COMPUTACIÓN
En la computación “tradicional” basada en sistemas centralizados una organización tenía que hacerse cargo de todas sus necesidades computaciones utilizando sus propios recursos, empleando para ello grandes y costosos servidores con una enorme potencia de cálculo. Es más, no podía hacer paralelismo ni balanceo de carga entre sus distintos servidores, pudiendo haber casos de recursos sobrecargados y ociosos al mismo tiempo; además de tener otros inconvenientes como: falta de escalabilidad, equipos muy caros, o falta de fiabilidad y robustez.
Parte de estos problemas son resueltos gracias a los sistemas paralelos, enmarcados habitualmente dentro de una única organización. En general, la mayoría de los trabajos sobre computación paralela y optimización están centrados en dos tipos de sistemas paralelos:
- Sistemas multiprocesador de memoria compartida. En este caso, los servicios ofrecidos por el sistema operativo son suficientes para desarrollar programas paralelos: se pueden usar lenguajes secuenciales con bibliotecas de threads o llamadas al sistema para escribir aplicaciones multithread o multiproceso que utilicen los distintos procesadores del sistema operativo. Otra opción consiste en usar lenguajes paralelos como Java.
- Sistemas distribuidos basados en clusters o redes de área local. En los sistemas distribuidos existe una cantidad enorme de aspectos a considerar, como la red de conexión (Ethernet, ATM, etc.), las distintas topologías (anillo, árbol, malla, etc.), los modelos de programación (paso de mensajes, RPC, memoria compartida distribuida, etc.), las bibliotecas de comunicación (MPI, PVM, sockets, etc.), lenguajes paralelos (Java, C++, etc.), middleware (CORBA, DCOM, RMI, etc.), e incluso tecnologías de Internet (XML, SOAP, Servicios Web, etc.).
En cambio, en la computación grid intervienen varias organizaciones, cada una con sus propios recursos computaciones, luego la complejidad se multiplica respecto a los sistemas distribuidos convencionales. Es importante aclarar, que aunque el grid y el P2P (Peer-To-Peer) parecen tener el mismo objetivo final (la organización coordinada de los recursos compartidos dentro de comunidades virtuales), se centran en distintas comunidades, por lo cual tienen distintos requerimientos y siguen caminos evolutivos distintos. Mientras los sistemas grid proporcionan varios servicios sofisticados a comunidades relativamente pequeñas y se centran en la integración de recursos muy potentes para proporcionar grandes calidades de servicio dentro de un entorno de confianza limitada; los famosos sistemas P2P tratan con muchos más participantes pero ofrecen servicios más limitados y especializados, están menos preocupados por la calidad del servicio, y hacen menos asunciones en cuanto a las relaciones de confianza entre recursos y usuarios.

.
FUNCIONAMIENTO DE LA COMPUTACIÓN GRID
El grid descansa sobre un software, denominado middleware, que asegura la comunicación transparente entre diferentes dispositivos repartidos por todo el mundo. La infraestructura grid integra un motor de búsqueda que no sólo encontrará los datos que el usuario necesite, sino también las herramientas para analizarlos y la potencia de cálculo necesaria para utilizarlas. Al final del proceso, el grid distribuirá las tareas de computación a cualquier lugar de la red en la que haya capacidad disponible y enviará los resultados al usuario.
El objetivo final del grid es poder utilizar recursos remotos que nos permitan realizar tareas que no podríamos abordar en nuestra máquina o centro de trabajo. La idea va más allá del simple intercambio de ficheros, se trata del acceso directo a software, ordenadores y datos remotos, así como el acceso y control de otros dispositivos (sensores, telescopios, etc.). Los recursos son agrupados dinámicamente para resolver problemas concretos, formando organizaciones virtuales. La existencia de conexiones de red rápidas y fiables es un requisito indispensable para poder exportar el grid a escala mundial y esto es algo que ahora por fin es viable, gracias a la proliferación de las redes de banda ancha (xDSL, HFC, LMDS, UMTS/HSDPA, satélite, etc.).
El verdadero interés del grid radica en el uso eficiente de los recursos. Se necesitan mecanismos para repartir el trabajo de forma automática y eficiente entre una gran cantidad de recursos, reduciendo las colas de espera de los distintos usuarios. En principio, tendremos información sobre los diferentes trabajos que se han enviado y, ya que todo se está ejecutando en ordenadores, podemos calcular cuál sería la asignación óptima de recursos.
Puesto que los recursos que son compartidos pertenecen a personas muy distintas, la seguridad es esencial, y se centra en los siguientes aspectos: política de accesos (qué es lo que se va a compartir, a quién se le permite el acceso, y bajo qué condiciones), autenticación (mecanismos para garantizar la identidad de un usuario o de un recurso concreto), y autorización (procedimiento para averiguar si una determinada operación es consistente con las relaciones que se han definido previamente de cara a compartir recursos). Otro aspecto muy importante es la estandarización: todas las aplicaciones que se ejecuten en un grid, deben poder funcionar en cualquier otro.
En la segunda generación de la red de acceso multimedia de banda ancha basado en ADSL, supone la consolidación de ésta tecnología y se pretende emplear servicios basados sólo en IP: como difusión de video sobre IP o telefonía de calidad sobre IP. Hoy en día, las interfaces Ethernet son mucho más baratas que las ATM y prácticamente igual de eficientes; además, es una tecnología menos compleja y más conocida. Precisamente, la introducción de ADSL se ha visto ralentizada, sobre todo en sus inicios, debido a los costes de infraestructura, así como a la lentitud y coste de su instalación y configuración.
ARQUITECTURA DE GRID
Habitualmente se describe la arquitectura del grid en términos de “capas”, ejecutando cada una de ellas una determinada función. Las capas más altas son las más cercanas al usuario y las inferiores las más próximas a las redes de computación, distinguiendo entre:
- Capa de aplicación. Formada por todas las aplicaciones de los usuarios, portales y herramientas de desarrollo que soportan esas aplicaciones. Es la capa que ve el usuario y que proporciona el llamado serviceware, que recoge las funciones generales de gestión tales como la contabilidad del uso del grid que hace cada usuario.
- Capa de middleware. Responsable de proporcionar herramientas que permiten que los distintos recursos participen de forma coordinada y segura en un entorno grid unificado.
- Capa de recursos. Constituida por los recursos que son parte del grid: ordenadores, supercomputadoras, sistemas de almacenamiento, catálogos electrónicos de datos, bases de datos, sensores, etc.
- Capa de red. Encargada de asegurar la conexión entre los recursos que forman el grid.
Para poder hacer todo lo anterior, las aplicaciones que se desarrollen para ser ejecutadas en un ordenador concreto, tendrán que adaptarse para poder invocar los servicios adecuados y utilizar los protocolos correctos. Sin embargo, una vez adaptadas al grid, miles de usuarios podrán usar las mismas aplicaciones, utilizando las capas de middleware para adaptarse a los posibles cambios en el tejido del grid.
Middleware
De todas estas capas, la más interesante es el middleware, el auténtico cerebro del grid, que se ocupa de las siguientes funciones:
- Encontrar el lugar conveniente para ejecutar la tarea solicitada por el usuario.
- Optimizar el uso de recursos que pueden estar muy dispersos.
- Organizar el acceso eficiente a los datos.
- Autenticar los diferentes elementos.
- Ejecutar las tareas.
- Monitorizar el progreso de los trabajos en ejecución.
- Gestionar automáticamente la recuperación frente a fallos.
- Avisar cuando se haya terminado la tarea y devolver los resultados.
El middleware está formado por muchos programas software; algunos de estos programas actúan como agentes (agents) y otros como intermediarios(brokers), negociando entre sí, de forma automática, en representación de los usuarios del grid y de los proveedores de recursos. Un elemento fundamental del middleware son los metadatos (datos sobre los datos), que contienen, entre otras cosas, toda la información sobre el formato de los datos y dónde se almacenan (a veces en varios sitios distintos). Los agentes individuales presentan los metadatos referidos a los usuarios, datos y recursos. Por otro lado, los intermediarios se encargan de las negociaciones entre máquinas para la autenticación y autorización de los usuarios, de definir los acuerdos de acceso a los datos y recursos y, en caso de que corresponda, el pago por los mismos. Cuando queda establecido el acuerdo, un intermediario planifica y las tareas de cómputo y supervisa las transferencias de datos necesarias para acometer cada trabajo concreto. Al mismo tiempo, una serie de agentes supervisores especiales optimizan las rutas a través de la red y monitorizan la calidad del servicio.

ESTANDARIZACIÓN
Actualmente, los estándares de grid los desarrolla el OGF (Open Grid Forum), organización nacida de la integración del GGF (Global Grid Forum) y la EGA (Enterprise Grid Alliance). El Foro es una comunidad de usuarios, desarrolladores, y vendedores liderando los esfuerzos de estandarización mundial del grid computing. La comunidad consiste en miles de individuos de la industria e investigación, representando más de 400 organizaciones en más de 50 países. El trabajo del OGF es llevado a cabo a través de grupos de trabajo organizados en comunidades, que desarrollan estándares y especificaciones en cooperación con otras organizaciones de estandarización, desarrolladores de software, y usuarios.
La arquitectura de sistemas grid basada en Servicios Web, conocida como OGSA (Open Grid Services Architecture), aparece como la referencia clave para los proyectos en desarrollo grid. Los Servicios Web es una arquitectura del W3C (Word Wide Web Consortium) para el desarrollo de servicios avanzados, a través de interfaces y protocolos consistentes y estándar, como: XML (eXtensible Markup Language), SOAP (Simple Object Access Protocol), WSDL (Web Service Description Language), y UDDI (Universal Description, Discovery and Integration). La implementación más famosa de Servicios Web es .NET, un proyecto de Microsoft para crear una nueva plataforma de desarrollo de software con énfasis en la transparencia de redes, independiente de la plataforma, y que permite un rápido desarrollo de aplicaciones.
La principal implementación de OGSA es el Globus Toolkit, una infraestructura de código abierto gratuita desarrollada por la Globus Alliance, que proporciona un conjunto de herramientas de programación Java (librerías, servicios y API), para construir fácil y rápidamente sistemas y aplicacionesgrid basándose en sus servicios y capacidades básicas; tales como la seguridad, la localización y gestión de los recursos y las comunicaciones. Los principales proyectos relacionados con grid, se están desarrollando en base al Globus Toolkit.
APLICACIONES DEL GRID
Las instituciones y organismos más interesadas en el desarrollo del grid son, principalmente, las que comparten un objetivo común y que, para poder alcanzarlo, lo más efectivo es compartir sus recursos: Gobiernos y organizaciones internacionales (respuesta a desastres, planificación urbana, etc.); sanidad (análisis rápido de imágenes médicas complejas, etc.); educación (creación de aulas virtuales, teleconferencias, etc.), empresas y grandes corporaciones (cálculos complejos, reuniones virtuales, etc.).
Los beneficios del grid, gracias a la integración de recursos distribuidos, están teniendo repercusión en muchísimos campos, de entre los que cabe destacar: medicina (imágenes, diagnosis y tratamiento), ingeniería genética y biotecnología (estudios en genómica y proteómica), nanotecnología (diseño de nuevos materiales a escala molecular), ingeniería (diseño, simulación, análisis de fallos y acceso remoto a instrumentos de control), y recursos naturales y medio ambiente (previsión meteorológica, observación del planeta, modelos y predicción de sistemas complejos).

El grid en los centros académicos y de investigación
La computación distribuida empezó a ser escalada a niveles globales con la madurez de Internet en los años 90. Dos proyectos en particular han demostrado que el concepto es totalmente viable y eficiente, incluso más de lo que los expertos auguraban en un principio: Distributed.net y SETI@home.
Distributed.net emplea miles de ordenadores distintos para crackear códigos de encriptación (RC5-64, CSC, DES-III, DES-II-1, DES-II-1, RC5-56, etc.). Fundado en 1997, el proyecto ha crecido hasta abarcar hoy en día más de 60.000 usuarios alrededor de todo el mundo. El poder de cómputo de Distributed.net ha ido creciendo hasta llegar a ser el equivalente a más de 160.000 computadoras PII 266MHz trabajando 24 horas al día, 7 días a la semana, y 365 días al año.
SETI@home ha sido el proyecto de computación distribuida más popular de la historia, cuyo objetivo era la búsqueda de vida extraterreste mediante la detección de su tecnología de comunicaciones, buscando patrones que demuestren inteligencia en las ondas de radio procedentes del espacio. Para ello, cualquier persona que quisiera colaborar podía descargarse un salvapantallas gratuito (de este modo aprovechaba los ciclos del ordenador sólo cuando éste no estaba en uso), que instalado en su ordenador analiza señales del espacio captadas con el radiotelescopio de Arecibo en Puerto Rico. El software se hizo público el 17 de mayo del 1999 y, desde entonces hasta su finalización el 15 de diciembre de 2005, más de 5 millones de voluntarios han instalado el programa en su ordenador, se han conseguido un total acumulado de dos millones de años de tiempo de CPU y se han analizado alrededor de 50 TB de datos, convirtiendo al proyecto en el mayor computador virtual de la historia de la humanidad por análisis realizados. En la actualidad, SETI@Home sigue en funcionamiento pero integrado en BOINC (Berkeley Open Infrastructure for Network Computing), un proyecto basado en recursos de redes abiertas con los mismos principios que el proyecto original. La nueva infraestructura continuará con la búsqueda de señales de radio extraterrestres, pero ahora además la potencia de CPU de los participantes se dedicará también a investigar sobre otras tareas, como el cambio climático, la astronomía y la cura de enfermedades.
El sector más involucrado en todo el mundo en la puesta a punto de plataformas grid en el desarrollo de aplicaciones adaptadas a esta nueva tecnología es, sin lugar a dudas, el de la investigación. En España las principales universidades e instituciones de investigación han participado intensamente en diversos proyectos sobre grid, tanto nacionales como internacionales, entre otros: “IRISGrid”, “Damien", “HealthGrid”, “CrossGrid”, “Enabling Grids for e-Science in Europe”, etc. Existen ya varios agentes grid disponibles para colaborar activamente en este tipo de proyectos, por ejemplo, en Grid.org de United Devices, cualquiera puede bajarse uno, instalarlo y configurarlo, para colaborar activamente en el desarrollo de esta fascinante tecnología y, a la vez, desempeñar una labor altamente solidaria (por ejemplo, ayudando al descubrimiento de nuevos fármacos y vacunas contra algunas de las enfermedades más terribles de nuestra Era).

Web-based SSH
Web-based SSH makes it possible to access Secure Shell (SSH) servers through standard web browsers. Respective clients are based on JavaScript/Ajax or JavaScript/WebSockets and can be used to access SSH servers from behind a firewall or proxy.
[]
Web-based SSH clients basically consist of the following parts:
- Client-side: Typically JavaScript and dynamic HTML pages are used to capture keystrokes, transmit messages to/from the server and display the results in the user's web browser.
- Server-side/Web application: Incoming requests are processed on the web application server. Keyboard events are forwarded to a secure shell client communicating with the connectedSSH server. Terminal output is either passed to the client where it is converted into HTML via JavaScript or it is translated into HTML by the server before it is transmitted to the client.
Client-side terminal emulation
Web-based SSH servers that utilize client-side terminal emulation typically transmit the raw terminal output from the SSH server directly to the client. This has the advantage of offloading the process of translating terminal output into HTML on to the client. The disadvantage of this method is that it is limited by the capabilities of JavaScript and it will use up a non-trivial amount of the client's CPU and memory to process the incoming character stream. It also relies on the client to keep track of the terminal state and respond to escape sequences.
Client-side terminal emulator example:
[]
Server-side terminal emulation
Web-based SSH servers that utilize server-side terminal emulation typically keep track of the terminal screen and state in memory and convert it to HTML either when a screen update occurs or when the client expressly requests an update. The advantage of this method is that the state of the terminal remains persistent even if the user connects to their existing session(s) from a different web browser. It also enables the server to act upon terminal output even if the user is disconnected[1]. The disadvantage of this method is that it uses up more CPU and memory on the server.
Links
lunes, 30 de abril de 2012
Comunicacion en sistemas Distribuidos
un sistema distribuido y un sistema multiusuario convencional es la comunicación de procesos. En un sistema convencional, la mayoría de los mecanismos desarrollados de alguna manera asumen la existencia de una memoria que comparten todos los procesos. Un ejemplo típico es el del productor-consumidor, donde la comunicación se realiza mediante un buffer almacenado en memoria común. El buffer más simple es el semáforo, que requiere tan sólo una palabra de memoria, el semáforo mismo. En un sistema distribuido, sin embargo, no existe en absoluto la memoria compartida, de modo que los mecanismos de comunicación de procesos deben ser rediseñados desde el principio
Sistemas Distribuidos - La Comunicación
Reporte de Actividades
Esta semana nos juntamos para probar el cluster entre todo el equipo cluster pero se algunos miembros del equipo no tenían instalado las herramientas y lo que se pensó hacer fue un bash para automatizar las tareas de instalación
Sistema de Archivos Distribuidos
Sistema de archivos distribuido o sistema de archivos de red es un sistema de archivos de computadoras que sirve para compartir archivos, impresoras y otros recursos como un almacenamiento persistente en una red de computadoras. El primer sistema de este tipo fue desarrollado en la década de 1970, y en 1985 Sun Microsystems creó el sistema de archivos de red NFS el cual fue ampliamente utilizado como sistema de archivos distribuido. Otros sistemas notables utilizados fueron el sistema de archivos Andrew (AFS) y el sistema Server Message Block SMB, también conocido como CIFS.
NFS
Primer sistema comercial de archivos en red (Sun 1984) maduro, estándar, multiplataforma que permite acceder y compartir archivos en una red C/S heterogénea como si estuvieran en un sólo disco, i.e. montar un directorio de un máquina-remota en una máquina local.
AFS
El Andrew file system es un sistema de archivos distribuido comercial (CMU 1983, Transarc 1989, IBM 1998) para compartir archivos de manera transparente, escalable e independiente de la ubicación real.
OpenAFS:
XCoda: Sistema de archivos distribuido experimental open-source derivativo de AFS (CMU 1987). Se distingue por soportar dispositivos móviles.
DCE DFS
Artículo principal: DCE Distributed File System.
DCE Distributed File System
es un sistema de ficheros distribuido de DCE que permite agrupar archivos repartidos en diferentes máquinas, en un espacio de nombres único. Está basado casi por completo en el sistema de ficheros AFS pero con ligeras diferencias.
miércoles, 18 de abril de 2012
Contribucion
Esta semana analice las redes de petri encontre una herramienta para la Simular
Enlace wiki
http://elisa.dyndns-web.com/progra/PetrA
Enlaces Adicionales:
http://antares.itmorelia.edu.mx/~fmorales/SisDisII/aRedesPetri01.pdf
http://www.ctr.unican.es/asignaturas/MC_ProCon/Doc/PETRI_3.pdf
Nominado:
Abraham : http://elisa.dyndns-web.com/progra/PetrA
Enlace wiki
http://elisa.dyndns-web.com/progra/PetrA
Enlaces Adicionales:
http://antares.itmorelia.edu.mx/~fmorales/SisDisII/aRedesPetri01.pdf
http://www.ctr.unican.es/asignaturas/MC_ProCon/Doc/PETRI_3.pdf
Nominado:
Abraham : http://elisa.dyndns-web.com/progra/PetrA
Red de Petri
Una Red de Petri es una representación matemática o gráfica de un sistema a eventos discretos en el cual se puede describir la topología de un sistema distribuido, paralelo o concurrente. La red de Petri esencial fue definida en la década de los años 1960 por Carl Adam Petri. Son una generalización de la teoría de autómatas que permite expresar un sistema a eventos concurrentes.
Una red de Petri está formada por lugares, transiciones,arcos dirigidos, y marcas o fichas que ocupan posiciones dentro de los lugares. Las reglas son: Los arcos conectan un lugar a una transición así como una transición a un lugar. No puede haber arcos entre lugares ni entre transiciones. Los lugares contienen un número finito o infinito contable de marcas. Las transiciones se disparan, es decir consumen marcas de una posición de inicio y producen marcas en una posición de llegada. Una transición está habilitada si tiene marcas en todas sus posiciones de entrada.
En su forma más básica, las marcas que circulan en una red de Petri son todas idénticas. Se puede definir una variante de las redes de Petri en las cuales las marcas pueden tener un color (una información que las distingue), un tiempo de activación y una jerarquía en la red.
La mayoría de los problemas sobre redes de Petri son decidibles, tales como el carácter acotado y la cobertura. Para resolverlos se utiliza un árbol de Karp-Miller. Se sabe que el problema de alcance es decidible, al menos en un tiempo exponencial.
Mediante una red de Petri puede modelazarse un sistema de evolución en paralelo o eventos concurrentes compuesto de varios procesos que cooperan para la realización de un objetivo común.
La presencia de marcas se interpreta habitualmente como presencia de recursos. El franqueo de una transición (la acción a ejecutar) se realiza cuando se cumplen unas determinadas precondiciones, indicadas por las marcas en las fichas (hay una cantidad suficiente de recursos), y la transición (ejecución de la acción) genera unas postcondiciones que modifican las marcas de otras fichas (se liberan los recursos) y así se permite el franqueo de transiciones posteriores.
Definición: Una red de Petri es un conjunto formado por  , donde
, donde  es un conjunto de fichas de cardinal
es un conjunto de fichas de cardinal 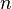 ,
,  un conjunto de transiciones de cardinal
un conjunto de transiciones de cardinal  ,
,  la aplicación de incidencia previa que viene definida como
la aplicación de incidencia previa que viene definida como
, donde es un conjunto de fichas de cardinal , un conjunto de transiciones de cardinal , la aplicación de incidencia previa que viene definida como |
y  la aplicación de incidencia posterior que viene definida como
la aplicación de incidencia posterior que viene definida como
la aplicación de incidencia posterior que viene definida como |
Definición: Una red marcada es un conjunto formado por  donde
donde  es una Red de Petri como la definida,
es una Red de Petri como la definida,  es una aplicación denominada marcado y
es una aplicación denominada marcado y
donde es una Red de Petri como la definida, es una aplicación denominada marcado y . . |
Se asocia a cada marca un número natural, en donde el número de marcas es descrita por la la cardinalidad del conjunto de marcas en la red.
Suscribirse a:
Entradas (Atom)




